 Improving Data Currency in Data Systems
Improving Data Currency in Data Systems
Data currency is imperative towards achieving up-to-date and accurate data analysis. Identifying and repairing stale data goes beyond simply having timestamps. Individual entities each have their own update patterns in both space and time. We develop a probabilistic system for identifying and cleaning stale values. We study currency in distributed environments where replicas of the same data item often exhibit varying consistency levels when executing read and write requests due to system availability and network limitations. When one or more replicas respond to a query, estimating the currency (or staleness) of the returned data item (without accessing the other replicas) is essential for applications requiring timely data. We are studying how data semantics influences temporal ordering of values towards accurate currency estimation.
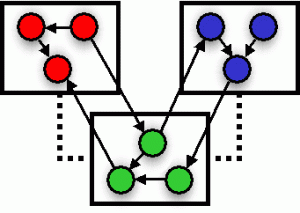
 Data Integrity over Graphs
Data Integrity over Graphs
Data dependencies play a fundamental role in preserving and enforcing data integrity. In relational data, integrity constraints such as functional dependencies capture attribute relationships based on syntactic equivalence. We explore new classes of data dependencies over graphs, possessing topological and syntactic constraints. We go beyond just equality relationships and study new classes of dependencies, such as: (1) Ontology Functional Dependencies (OFDs) that capture attribute relationships based on synonym and hierarchical (is-a) relationships defined in an ontology; (2) Temporal Graph Functional Dependencies (TGFDs), to capture topological and attribute constraints that persist over time; and (3) Ontological Graph Keys (OGKs) that extend conventional graph keys by ontological subgraph matching between entity labels and an external ontology.
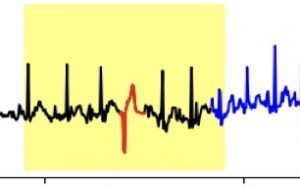 Differentiating Concept Drift from Anomalies
Differentiating Concept Drift from Anomalies
Traditional time series analysis are unaware of concept drift, based on the assumption that time series concepts are stationary, and data values follow a fixed probability distribution. This assumption does not hold in practice. For example, temperature changes between seasons demonstrate a gradual increase from winter to spring, changes in workplace electricity usage from weekday to weekend exhibit an abrupt decrease due to a change in employee work patterns. We study the problem of anomaly detection in the presence of concept drift.
 Data Preparation and SQL Understanding in LLMs
Data Preparation and SQL Understanding in LLMs
The rise of large language models (LLMs) has significantly impacted various domains, making computational tasks more accessible. While LLMs demonstrate impressive generative capabilities, it is unclear how well they are able to understand and perform logical reasoning for data preparation and SQL tasks.
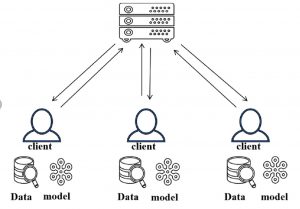 Freshness-based Client Selection in Vertical Federated Learning
Freshness-based Client Selection in Vertical Federated Learning
In federated learning, instead of uniformly selecting clients to train at each round, we consider the freshness (or conversely, the staleness) of data at each client, to improve model convergence and accuracy.
 A Data System for Blood Monitoring
A Data System for Blood Monitoring
According to the 2020 Auditor General Report on Blood Management and Safety, hospitals are using a variety of information systems to monitor blood inventory, usage, and patient clinical data. This heterogeneity has led to disparate, and disjoint systems hindering data sharing among hospitals, Canadian Blood Services (CBS), and government. Furthermore, these localized views and limited data exchange pose challenges to meet current and predicted demand across hospitals, and to ensure that usage of blood components and products adhere to provincial guidelines. We develop a data system to understand how blood components and products are used to treat specific conditions, follow-on prognosis, and clinical outcomes with respect to patient demographics.
Sponsors and Industry Collaborators

